Trained Skills for this project





Legal Text Summarization

Project Backstory
This project has an interesting arc to it. It was the first project I ever made that was 100% percent initiated by myself. During a conversation with fellow students, we came to the realisation that we all just click on the user agreement of basically any program or company we know. We can't really say what this agreement implies. What's even worse, we have no idea what companies do with the data we provide them.
Being Digital Innovation, this presented me with an opportunity. What if I just asked the question myself and pitch it to our teachers. After initial enthusiasm, we also found a partner to collaborate with and who could assist us with their field knowledge. Coached by Kenan Elrici from 'Algorhythm', I created a Streamlit web application with a single goal: Can we create an NLP language model that can summarize and ultimately simplify legal documentation?
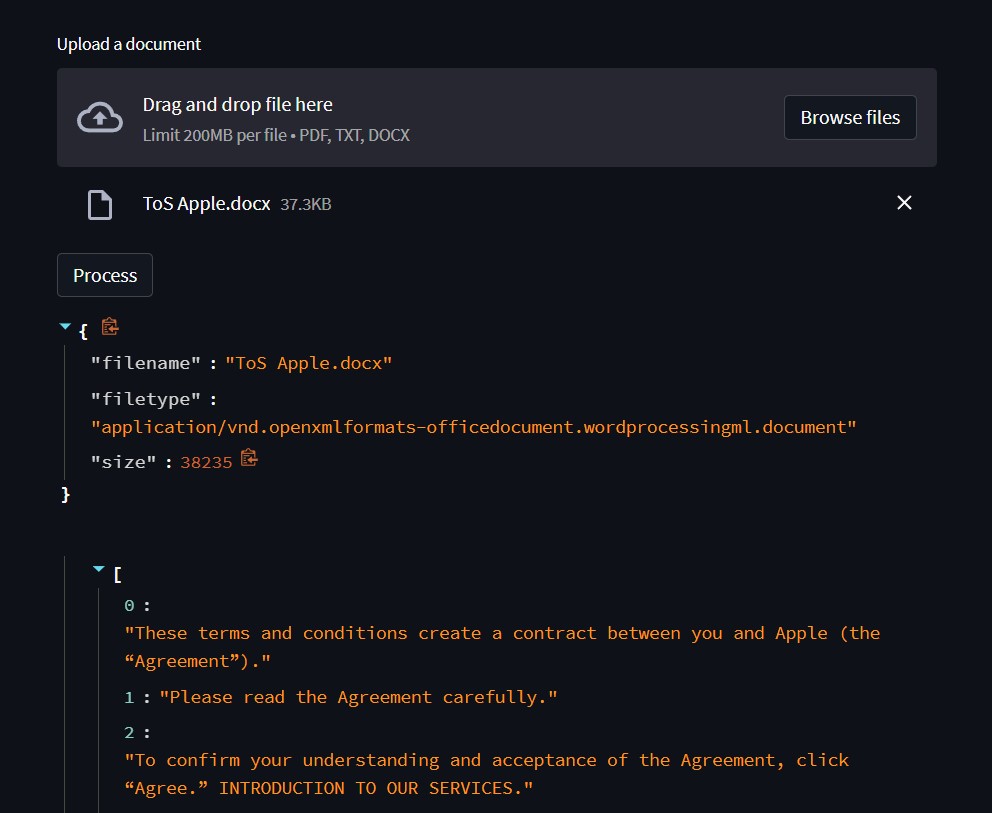
The lack of labeled data
In the early stages of the project, I learned about Natural Language Processing and its basic techniques. I also came into contact with the concept of Transformers and the HuggingFace community. They provide many different artificial intelligence models that can be freely used and finetuned for specific use cases.
After the early exploratory phase I discovered that although there are many summarization models available, it mostly boils down to the same problem: Summarizers give an overall coherent 'overview' of what the entire document is about. This is however not the goal in this case. The goal is a short list of bullet points that states the most imporant 'obligations' in both directions of the user-company relationship.
Scoring mechanism
So with the help of the TOSDR.org API I found a way to store a lot of textual data of various companies. I withheld the Terms of Service and Privacy Policy, as those seemed the most interesting from a consumer standpoint. Using NLP techniques such as tokenization en TF-IDF, I dug deeper into all that data and started discovering patterns (frequent tokens en ngrams) that provided more insight into what these documents were about.
We then came up with a pipeline for the project that consisted in the first place of the actual creation of a labeled dataset. But how to 'label' the information in these documents? The approach we took was to score each sentence based on the weights of the tokens it was made up from. By adding our own bias, we could steer the the summarizer into paying more attention to what we were actually interested in.